Introduction
The transition from traditional IT operations to high-velocity reliability management is a defining shift in modern software engineering. The Certified Site Reliability Engineer is an industry-standard credential designed to bridge the gap between software development and systems operations. This guide is crafted for professionals who need to navigate the complexities of distributed systems, cloud-native architectures, and the culture of reliability. Whether you are an individual contributor or a technical leader, understanding the roadmap provided by SreSchool is essential for making informed career decisions. This comprehensive overview maps out the certification levels, provides a technical deep dive into core competencies, and evaluates the real-world impact of becoming a practitioner. In an era where downtime is measured in lost revenue and brand reputation, mastering the art of reliability is no longer optional.
What is the Certified Site Reliability Engineer?
The Certified Site Reliability Engineer is more than just a certificate of completion; it is a rigorous validation of an engineer’s ability to maintain system health at scale. This program focuses on the practical application of Google’s SRE principles, such as service level objectives, error budgets, and the automation of manual operational tasks. It exists to provide a standardized framework for managing large-scale production environments where stability and speed must coexist. Unlike generic cloud certifications, this path focuses specifically on the intersection of engineering and operations through a reliability lens. By completing this program, engineers demonstrate they possess the mindset required to handle complex failures, optimize performance, and manage risk in high-stakes enterprise environments.
Who Should Pursue Certified Site Reliability Engineer?
This certification is designed for a broad spectrum of technical professionals, ranging from junior software developers to veteran systems administrators. DevOps engineers, cloud architects, and platform engineers will find the professional tracks particularly valuable for validating their architectural skills. In India and across the global market, engineering managers and technical leaders are also pursuing foundational levels to better understand how to structure their teams for high availability. It is equally relevant for security professionals and data engineers who need to ensure their specialized systems meet the rigorous uptime requirements of modern microservices. Whether you are just starting your journey or looking to cement your status as a principal engineer, this curriculum offers a structured path for every experience level.
Why Certified Site Reliability Engineer is Valuable
In the current technological climate, the demand for professionals who can manage complex distributed systems far outweighs the supply, making this credential highly valuable. Organizations across all sectors are moving away from reactive firefighting toward proactive reliability engineering, which ensures long-term career longevity for certified practitioners. The program provides a tool-agnostic understanding of reliability that allows professionals to stay relevant even as specific technologies or cloud providers change. It also offers a significant return on investment through career advancement and the ability to command premium salaries in the competitive tech market. Ultimately, the value lies in the shift from being a technician to becoming a reliability strategist who can drive business outcomes through technical excellence.
Certified Site Reliability Engineer Certification Overview
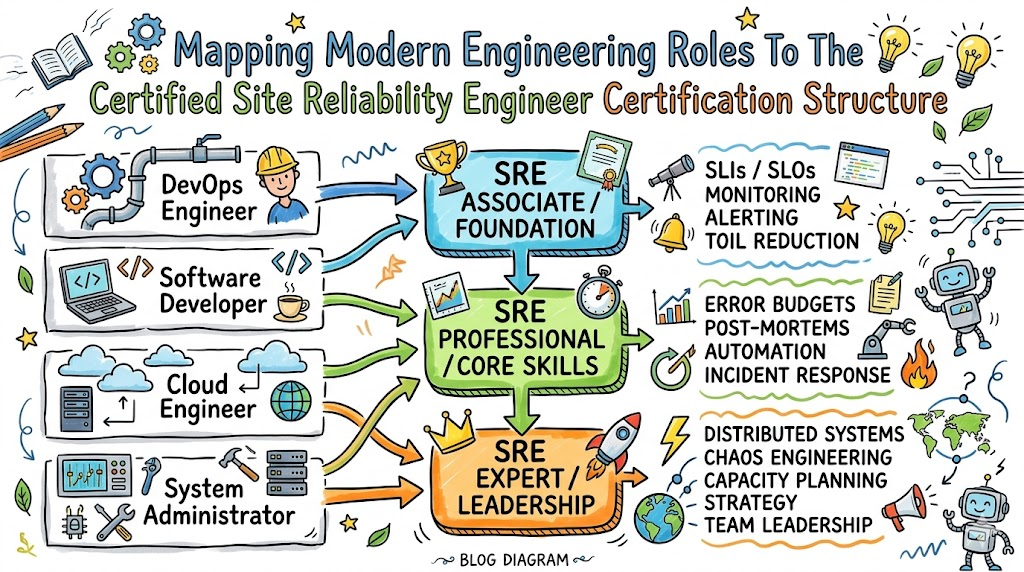
It is structured into multiple levels of proficiency, including Foundational, Associate, and Professional tiers, ensuring a logical progression of skills. Each certification track is designed to mirror real-world production scenarios, focusing on hands-on labs and performance-based assessments rather than simple theoretical knowledge. The ownership of the certification resides with industry-leading practitioners who ensure the curriculum is updated to reflect modern enterprise practices and cloud-native workflows. This structure provides a transparent and verifiable way for employers to assess the technical competence of their reliability teams.
Certified Site Reliability Engineer Certification Tracks & Levels
The certification hierarchy is divided into three main tracks to cater to different stages of professional growth. The Foundational level serves as an entry point, establishing a common language and understanding of core SRE principles across the organization. The Associate level targets practitioners who are actively managing production workloads, focusing on automation, monitoring, and incident response. Finally, the Professional and Advanced levels are intended for architects and leaders who are responsible for designing resilient systems and driving cultural change at scale. These levels align with typical career progression paths, allowing an engineer to move from a junior role to a senior lead or architect with a clear educational roadmap.
Complete Certified Site Reliability Engineer Certification Table
| Track | Level | Who it’s for | Prerequisites | Skills Covered | Recommended Order |
| Core SRE | Foundational | IT Beginners / Managers | None | SLIs, SLOs, Error Budgets | 1 |
| SRE Practitioner | Associate | DevOps / Cloud Engineers | Foundational | Automation, Monitoring | 2 |
| SRE Specialist | Professional | Senior SREs / Leads | Associate | Distributed Systems, Chaos | 3 |
| SRE Architect | Advanced | Principal Engineers | Professional | Enterprise Scalability, GSLB | 4 |
| FinOps SRE | Specialty | FinOps Practitioners | Foundational | Cloud Cost, Unit Economics | Optional |
| DevSecOps SRE | Specialty | Security Engineers | Foundational | Security Automation, IAC | Optional |
Detailed Guide for Each Certified Site Reliability Engineer Certification
Foundational Level
Certified Site Reliability Engineer – Foundation
What it is
The Foundation certification validates a candidate’s grasp of the fundamental terminology and cultural concepts of SRE. It ensures that the professional understands the basic mechanics of how reliability is measured and maintained in a modern software lifecycle.
Who should take it
This is essential for junior developers, project managers, and systems administrators who are new to the world of site reliability engineering. It is also highly recommended for recruiters and HR professionals who need to identify qualified talent in the DevOps space.
Skills you’ll gain
- Defining Service Level Indicators (SLIs) and Objectives (SLOs).
- Calculating and managing Error Budgets to balance risk.
- Understanding the impact of Toil and how to measure it.
- Basics of blameless post-mortem culture and incident response.
Real-world projects you should be able to do
- Create a reliability report for a small-scale application using SLOs.
- Conduct a basic toil audit to identify manual tasks for automation.
- Draft a post-mortem document for a simulated minor service disruption.
Preparation plan
- 7-14 days: Reviewing the official handbook and taking practice quizzes.
- 30 days: Participating in foundational workshops and group study sessions.
- 60 days: Deep dive into case studies of major system failures and recovery strategies.
Common mistakes
- Focusing too much on specific cloud provider tools rather than the principles.
- Neglecting the cultural aspects like psychological safety and blamelessness.
Best next certification after this
- Same-track option: Associate Certified Site Reliability Engineer.
- Cross-track option: Foundation DevSecOps Practitioner.
- Leadership option: Technical Team Lead Fundamentals.
Associate Level
Certified Site Reliability Engineer – Associate
What it is
The Associate level certification focuses on the technical implementation of reliability principles using automation and observability tools. It bridges the gap between understanding SRE theory and applying it to live production environments.
Who should take it
This is targeted at DevOps engineers and systems administrators with 1-2 years of experience who want to specialize in reliability. It is also ideal for developers who are taking on more operational responsibilities in a “you build it, you run it” environment.
Skills you’ll gain
- Implementing observability stacks including metrics, logs, and traces.
- Developing automated incident remediation scripts using Python or Go.
- Managing infrastructure as code using tools like Terraform or Pulumi.
- Configuring advanced alerting logic to reduce alert fatigue.
Real-world projects you should be able to do
- Build a self-healing infrastructure component that restarts on failure.
- Deploy a centralized logging system for a microservices cluster.
- Automate the provisioning of a production-ready cloud environment.
Preparation plan
- 7-14 days: Focused lab work on observability and alerting tools.
- 30 days: Implementing end-to-end automation projects in a sandbox.
- 60 days: Participating in a simulated “Game Day” to test incident response.
Common mistakes
- Hardcoding values in automation scripts instead of using environment variables.
- Creating too many alerts that lead to engineer burnout and fatigue.
Best next certification after this
- Same-track option: Professional Certified Site Reliability Engineer.
- Cross-track option: Certified FinOps Associate.
- Leadership option: SRE Manager Certification.
Professional/Specialty Level
Certified Site Reliability Engineer – Professional
What it is
The Professional certification is a high-level credential that validates expertise in distributed systems architecture and advanced chaos engineering. It is intended for those who design the reliability frameworks used by entire organizations.
Who should take it
Senior SREs, Lead Cloud Architects, and Principal Engineers are the primary audience for this level. These are individuals who are responsible for the availability of mission-critical services at a global scale.
Skills you’ll gain
- Designing multi-region and multi-cloud resilient architectures.
- Executing advanced chaos engineering experiments to find hidden failures.
- Managing global traffic routing and load balancing strategies.
- Leading organizational change to adopt SRE practices at scale.
Real-world projects you should be able to do
- Design a disaster recovery plan for a multi-region database system.
- Implement a chaos mesh in a production-like Kubernetes environment.
- Architect a global load balancing solution with automated failover.
Preparation plan
- 7-14 days: Reviewing advanced white papers on distributed systems theory.
- 30 days: Hands-on labs focusing on global traffic management and chaos tools.
- 60 days: Documenting a complex architectural design for a peer-review session.
Common mistakes
- Ignoring the cost implications of high-availability architectural designs.
- Failing to account for data consistency issues during regional failovers.
Best next certification after this
- Same-track option: Advanced Reliability Expert.
- Cross-track option: MLOps Professional Specialist.
- Leadership option: Director of Reliability Engineering Track.
Choose Your Learning Path
DevOps Path
The DevOps path emphasizes the integration of continuous delivery with reliability, ensuring that the speed of deployment does not compromise system stability. It focuses on building robust pipelines that automatically test for performance and reliability before code reaches production. This path is ideal for engineers who want to bridge the gap between feature development and operational excellence through technical automation.
DevSecOps Path
In the DevSecOps path, security is treated as a fundamental component of reliability, integrating automated security checks into the existing SRE workflow. Professionals on this path learn how to manage compliance as code and protect distributed systems from evolving threats without slowing down delivery. This is a critical specialization for those working in regulated industries like fintech or healthcare.
SRE Path
The pure SRE path is dedicated to the scientific management of production systems, focusing heavily on metrics, automation, and the reduction of manual toil. It is designed for those who want to master the mathematical approach to risk management and the architecture of self-healing systems. This path follows the original Google framework closely, emphasizing data-driven decision-making.
AIOps Path
The AIOps path explores the intersection of artificial intelligence and operations, teaching engineers how to use machine learning models to predict and resolve system issues. It focuses on the automation of anomaly detection and the use of AI to filter noise from massive data streams. This path is becoming essential as systems grow too complex for manual human monitoring.
MLOps Path
The MLOps path is a specialized track for engineers who support machine learning workloads, ensuring the reliability of data pipelines and model inference services. It addresses the unique challenges of model drift, data quality, and the high-performance computing requirements of AI applications. This is a high-growth area for engineers looking to support the next generation of AI-driven products.
DataOps Path
DataOps focuses on the reliability of data delivery, applying SRE principles to the lifecycle of data from ingestion to consumption. It ensures that data pipelines are monitored for quality and latency, preventing the “garbage in, garbage out” problem in analytics. This path is vital for organizations that rely on real-time data for critical business intelligence.
FinOps Path
The FinOps path addresses the economic side of site reliability, teaching engineers how to balance high availability with cloud cost management. It focuses on the concept of unit economics and how to optimize infrastructure spending without sacrificing performance or stability. As cloud costs continue to rise, FinOps skills are increasingly mandatory for senior reliability leaders.
Role → Recommended Certified Site Reliability Engineer Certifications
| Role | Recommended Certifications |
| DevOps Engineer | CSRE Foundational + Associate + DevSecOps Specialist |
| SRE | CSRE Foundational + Associate + Professional |
| Platform Engineer | CSRE Associate + Professional + FinOps Specialist |
| Cloud Engineer | CSRE Foundational + Associate + SRE Specialist |
| Security Engineer | CSRE Foundational + DevSecOps Specialist |
| Data Engineer | CSRE Foundational + DataOps Specialist |
| FinOps Practitioner | CSRE Foundational + FinOps Specialist |
| Engineering Manager | CSRE Foundational + SRE Leadership Track |
Next Certifications to Take After Certified Site Reliability Engineer
Same Track Progression
Once you have mastered the foundational and associate levels, the next step is to pursue deep specialization in areas like high-scale traffic management or advanced chaos engineering. Continuing within the SRE track allows you to become a principal expert who can solve the most difficult reliability problems in the industry. This progression ensures you remain at the cutting edge of the field as distributed systems continue to evolve in complexity.
Cross-Track Expansion
Reliability does not exist in isolation, so expanding your expertise into security (DevSecOps) or cloud economics (FinOps) is a highly strategic move. This cross-disciplinary approach makes you a more versatile professional who can contribute to broader business goals beyond just keeping the servers running. Engineers who can speak the language of both security and finance are often fast-tracked for high-level consulting or architecture roles.
Leadership & Management Track
For those who want to move into people management, the leadership track focuses on building and scaling SRE organizations. This includes learning how to hire the right talent, managing team budgets, and advocating for reliability at the executive level. Transitioning to leadership requires a shift from technical execution to strategic thinking, ensuring that the culture of the entire company supports reliability as a core value.
Training & Certification Support Providers for Certified Site Reliability Engineer
- DevOpsSchool
DevOpsSchool is a globally recognized training provider that offers extensive resources for aspiring site reliability engineers. They provide a mix of live instructor-led sessions and self-paced content that covers the entire SRE spectrum from foundation to professional levels. Their community-driven approach ensures that students have access to a network of mentors and peers for long-term career support. - Cotocus
Cotocus specializes in high-end technical consulting and corporate training, providing tailored learning paths for organizations looking to adopt SRE practices. They focus on hands-on labs that simulate real-world production environments, ensuring that engineers are prepared for the pressures of live systems. Their curriculum is highly practical and aligned with the latest industry trends in cloud-native architecture. - Scmgalaxy
Scmgalaxy provides a wealth of community resources, including blogs, tutorials, and certification guides that are invaluable for self-study. They focus on the practical tools of the trade, helping engineers master the automation and configuration management skills required for modern operations. Their platform is a great starting point for anyone looking to understand the broader DevOps and SRE ecosystem. - BestDevOps
BestDevOps offers curated training programs that focus on the most essential skills needed to pass the CSRE exams and succeed in the workplace. They emphasize efficiency in learning, providing streamlined content that cuts through the noise of the complex IT landscape. Their trainers are experienced practitioners who bring real-world insights into every session they conduct. - devsecopsschool.com
devsecopsschool.com is the premier provider for engineers looking to specialize in the intersection of security and reliability. They offer deep-dive courses on automated security testing, secrets management, and compliance as code. Their training is essential for SREs who want to ensure their systems are not only reliable but also secure from modern cyber threats. - sreschool.com
sreschool.com is the primary source for the Certified Site Reliability Engineer program, offering the official curriculum and assessment platform. They provide the most direct path to certification, with content that is strictly aligned with the exam objectives. By training here, you are guaranteed to receive the most authoritative and up-to-date information available in the field. - aiopsschool.com
aiopsschool.com leads the industry in training for the next generation of operations engineers, focusing on the power of artificial intelligence. Their courses teach students how to build and deploy AIOps solutions that automate incident detection and resolution. This is the ideal provider for forward-thinking engineers who want to stay ahead of the technical curve. - dataopsschool.com
dataopsschool.com offers specialized training for data engineers and SREs who manage large-scale data platforms. They focus on applying reliability principles to data pipelines, ensuring data quality and availability for the entire enterprise. Their certifications are highly relevant for companies that treat data as a mission-critical asset for decision-making. - finopsschool.com
finopsschool.com provides the training needed to master the discipline of cloud financial management, a critical skill for modern SREs. They teach engineers how to optimize cloud infrastructure costs without compromising the reliability or performance of the services. Their curriculum is essential for anyone responsible for managing the financial impact of cloud-native systems.
Frequently Asked Questions
1. What is the average time required to complete the CSRE Foundation?
Most professionals with a basic IT background can complete the Foundation level in two to four weeks of dedicated study.
2. Is there a physical lab requirement for the Associate exam?
Yes, the Associate level typically includes performance-based labs where you must solve real problems in a live cloud environment.
3. Does the certification cover specific tools like Prometheus or Grafana?
While the certification is principle-based, these industry-standard tools are frequently used in the labs to demonstrate observability concepts.
4. Can I jump directly to the Professional level?
Generally, it is recommended to follow the sequence, as each level builds on the technical and cultural knowledge of the previous one.
5. How much does the Certified Site Reliability Engineer exam cost?
Pricing can vary by region and level, so it is best to check the official website for the most current fee structure.
6. What is the passing score for the certification exams?
The passing score is typically set at 70%, but this can vary based on the complexity and weighting of specific exam versions.
7. Is the certification recognized by major cloud providers like AWS or Google?
Yes, the CSRE is respected as a vendor-neutral credential that complements platform-specific certifications by focusing on the operational mindset.
8. Are there any renewal requirements for the CSRE?
The certification usually requires renewal every two years through continuing education or by passing a higher-level exam in the track.
9. Can I take the training in Hindi or other regional languages?
Many providers like DevOpsSchool offer support and training in multiple languages to cater to a global and diverse audience of engineers.
10. What is the difference between SRE and DevOps certifications?
DevOps certifications focus on the culture of collaboration, while SRE certifications focus on the specific engineering practices used to maintain reliability.
11. Is there a community forum for CSRE candidates?
Yes, platforms like Sreschool and Scmgalaxy host forums where candidates can ask questions, share tips, and network with other professionals.
12. Does the program help with job placement?
Many training providers offer career support, including resume reviews and interview preparation, to help certified individuals find roles in the industry.
FAQs on Certified Site Reliability Engineer
1. How does the CSRE program define the role of an Error Budget?
The error budget is a critical mathematical tool used to balance the speed of development with the necessity of system stability. It provides a clear, data-driven threshold for how much downtime or failure is acceptable within a specific period. By using an error budget, teams can make objective decisions about when to launch new features and when to focus exclusively on reliability improvements. This concept is central to the CSRE curriculum because it removes the traditional friction between developers and operations teams by providing a shared goal.
2. What are the key differences between the Associate and Professional levels?
The Associate level is focused on the “how” of reliability, emphasizing the technical tools and automation scripts needed to manage a production environment. The Professional level, however, focuses on the “what” and “why” of distributed systems architecture and organizational strategy. Professionals are expected to design complex, multi-region systems that can withstand catastrophic failures, whereas Associates focus on managing the day-to-day uptime of specific services. The Professional level also introduces advanced topics like chaos engineering and leadership, which are not covered in the Associate tier.
3. Why is blameless culture taught as a technical skill in this certification?
A blameless culture is essential for reliability because it ensures that teams can identify the true root causes of failures without fear of punishment. In the CSRE program, this is treated as a technical skill because it directly impacts the quality of post-mortems and the speed of system improvement. Without a blameless culture, engineers may hide mistakes, leading to repeated outages and a lack of long-term stability. The certification teaches you how to facilitate these discussions and document findings in a way that leads to permanent technical remediations.
4. How does the certification address the challenge of “Toil” in operations?
Toil is defined as manual, repetitive, and automatable work that provides no long-term value to the system. The CSRE program teaches engineers how to identify toil through data collection and how to prioritize its elimination through automation. By reducing toil, engineers can spend more of their time on high-value projects that improve the system’s architecture and scalability. This focus on toil reduction is a core tenant of the SRE mindset and is one of the primary ways the certification helps organizations improve their operational efficiency.
5. What is the significance of Service Level Objectives (SLOs) in the curriculum?
SLOs are the internal goals that define the desired level of reliability for a service, acting as the foundation for the entire SRE framework. The certification teaches you how to select the right Service Level Indicators (SLIs) to measure what truly matters to the end user. You will learn how to set realistic SLOs that provide a high level of service without being prohibitively expensive or difficult to maintain. Mastering the art of setting and monitoring SLOs is essential for anyone who wants to manage production systems professionally.
6. How does the CSRE program prepare engineers for incident response?
The program provides a structured approach to incident management, including roles like Incident Commander and Scribe to ensure clear communication during an outage. You will learn how to use observability tools to quickly identify the source of a problem and how to implement automated remediation to reduce the time to recovery. The goal is to move from chaotic, unorganized responses to a disciplined, military-style operation that minimizes the impact on the customer. This training is vital for reducing the stress and financial loss associated with production incidents.
7. Is the Certified Site Reliability Engineer program relevant for on-premise environments?
While the curriculum has a strong focus on cloud-native practices, the core principles of reliability, automation, and monitoring are equally applicable to on-premise data centers. The program teaches you how to apply a modern engineering mindset to any infrastructure, regardless of where it is hosted. Many enterprise organizations use these principles to modernize their legacy systems and bring them up to the same reliability standards as their cloud applications. The “reliability-first” approach is universal and provides value in any environment where uptime is a priority.
8. What impact does this certification have on a professional’s career trajectory?
Earning a CSRE often acts as a catalyst for moving into high-impact roles like Lead SRE, Platform Architect, or Director of Reliability. It provides a formal validation of skills that are otherwise difficult to prove, giving you a competitive edge in the job market. Many organizations now list SRE certification as a preferred or required qualification for their senior technical roles. Beyond the title change, the program gives you the confidence and language to influence organizational strategy and lead high-performing teams in the most demanding technical environments.
Final Thoughts: Is Certified Site Reliability Engineer Worth It?
In the fast-moving world of IT, it is easy to get caught up in the hype of new tools and frameworks, but reliability remains the ultimate metric of success. The Certified Site Reliability Engineer program offers a disciplined, experience-driven path to mastering the most critical aspect of modern engineering. Based on years of industry observation, I can confidently say that the shift toward SRE is not a temporary trend but a fundamental change in how software is delivered and maintained. If you are committed to the long-term health of systems and your own professional growth, this certification is a worthy investment. The curriculum is designed to push you beyond your comfort zone, forcing you to think about failures before they happen and automation before the toil becomes unbearable. It is a rigorous journey, but the skills you gain will serve you throughout your entire career, regardless of which cloud provider or programming language becomes dominant. My advice is to approach this as a student of the craft, focusing on the principles that drive reliability at the highest levels. The tech industry needs more engineers who can balance innovation with stability, and this certification is your roadmap to becoming one of them.